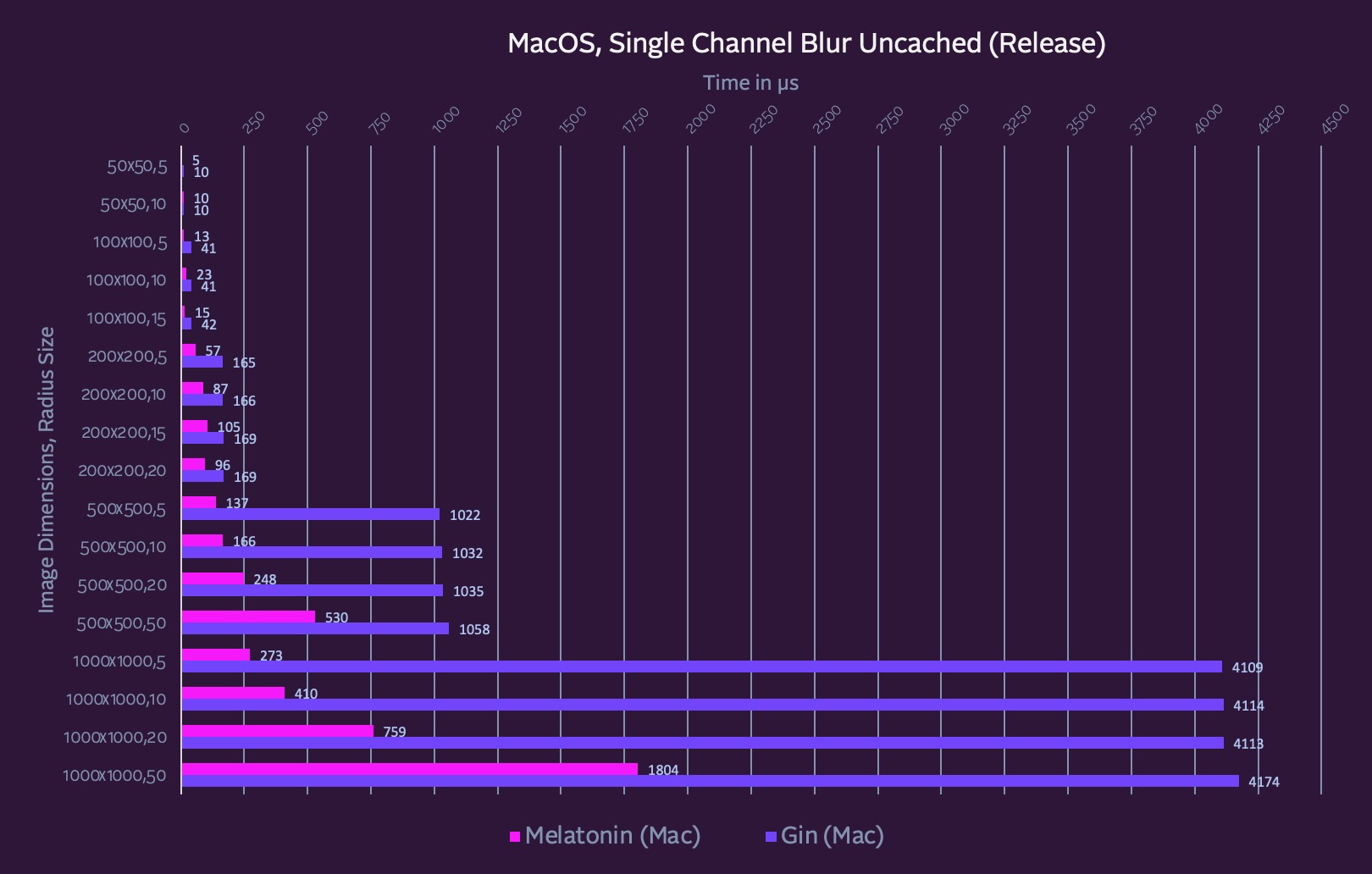
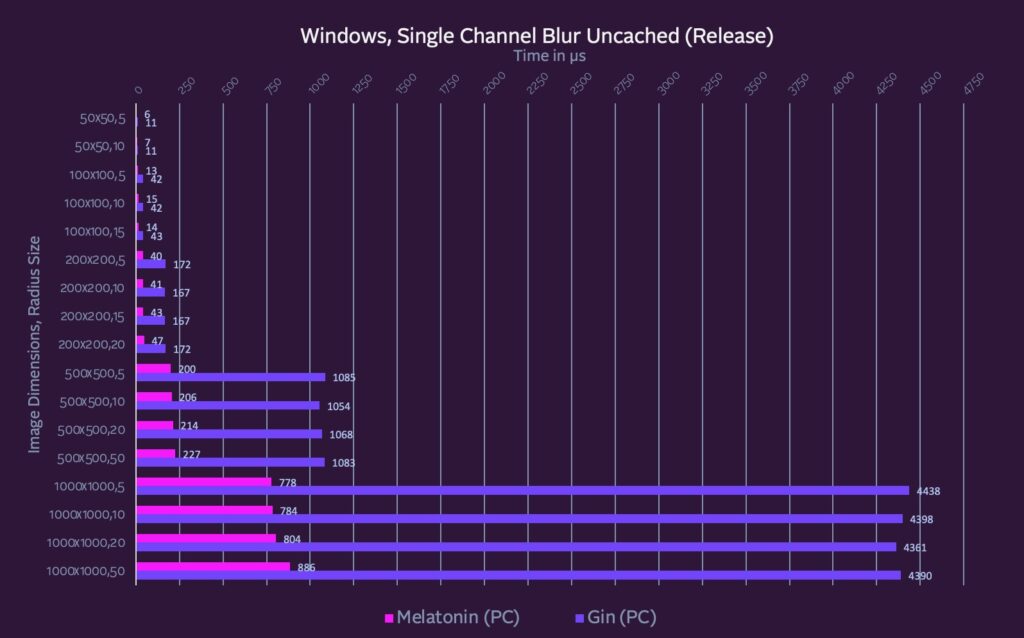
These are single channel blurs.
My #2 performance goal was for single channel blurs underlying shadows themselves to take µs, not ms.
You can also think of these as the timings for the first time a shadow is built with a blur. Optimizing these larger image sizes ensures that drop shadows won’t be a cause for dropped frames on their first render (and can even be animated).
Stack Blur (and in particular the Gin implementation) is already very optimized, especially for smaller dimensions. It’s hard to beat the raw blur performance on smaller images like a 32x32px (although caching the blur is still very much worth it). However, as image dimensions scale, Stack Blur gets into the ms, even on single channels.
Melatonin Blur stays under 1ms for the initial render of most realistic image sizes and radii.
Leave a Reply